Duplicate data can cause a number of issues when working with SQL Server tables. Not only does it take up unnecessary space, but it can also lead to confusion and errors in reporting. In this blog post, we will explore several different ways to delete duplicate rows in SQL Server.
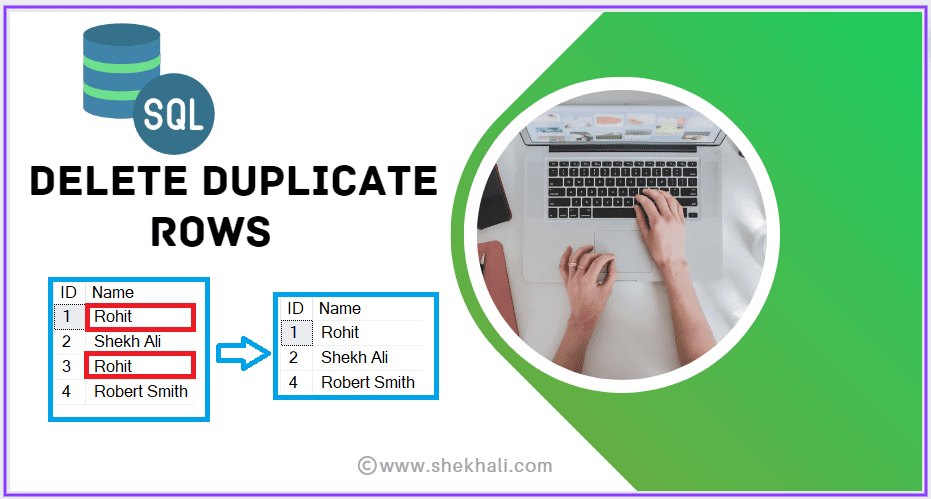
Table of Contents
Method 1: Using the DELETE Statement
The simplest way to delete duplicate rows is by using the DELETE statement. To do this, you will need to use a subquery that retrieves the duplicate rows you want to delete. For example:
Syntax:
DELETE FROM Table_Name
WHERE Column_Name IN
(SELECT Column_Name
FROM Table_Name
GROUP BY Column_Name
HAVING COUNT(*) > 1)
Example:
Let’s say we have a table called “Employees” with the following columns: “ID”, “Name”, “Email”, and “Department”.
CREATE TABLE Employees (
ID INT PRIMARY KEY,
Name VARCHAR(255),
Email VARCHAR(255),
Department VARCHAR(255)
);
INSERT INTO Employees (ID, Name, Email, Department)
VALUES (1, 'Rohit', 'rohit@example.com', 'HR'),
(2, 'Shekh Ali', 'shekh@example.com', 'IT'),
(3, 'Rohit', 'rohit@example.com', 'HR'),
(4, 'Robert Smith', 'robert.smith@example.com', 'Sales');
The following is an example of how the table would look before and after running the SQL script.
| Id | Name | Department | |
|---|---|---|---|
| 1 | Rohit | rohit@example.com | HR |
| 2 | Shekh Ali | shekh@example.com | IT |
| 3 | Rohit | rohit@example.com | HR |
| 4 | Robert Smith | robert.smith@example.com | Sales |
If you run the following Delete script:
DELETE FROM Employees
WHERE Email IN
(SELECT Email
FROM Employees
GROUP BY Email
HAVING COUNT(*) > 1)
The result would be like this:
| Id | Name | Department | |
|---|---|---|---|
| 2 | Shekh Ali | shekh@example.com | IT |
| 4 | Robert Smith | robert.smith@example.com | Sales |
The script deleted the rows with duplicate email addresses (Rohit’s email) and will leave only the unique email addresses in the table.
Method 2: Using the GROUP BY Clause
Another way to delete duplicate rows is by using the GROUP BY clause. This method is similar to the previous one, but it uses the GROUP BY clause instead of a subquery.
Syntax:
DELETE FROM Table_Name
WHERE Column_Name NOT IN
(SELECT MIN(Column_Name)
FROM Table_Name
GROUP BY Column_Name)
Example:
To delete the duplicate rows from the “Employees” table by using the GROUP BY clause, we can use the following SQL query:
DELETE FROM Employees
WHERE ID NOT IN (
SELECT MIN(ID)
FROM Employees
GROUP BY Email
);
In the above query, we are using the GROUP BY clause to group the records by the “Email” column, and then using the MIN() function to select the ID of the first record for each group. The subquery returns the ID of the unique records and the NOT IN operator is used to exclude those records from deletion.
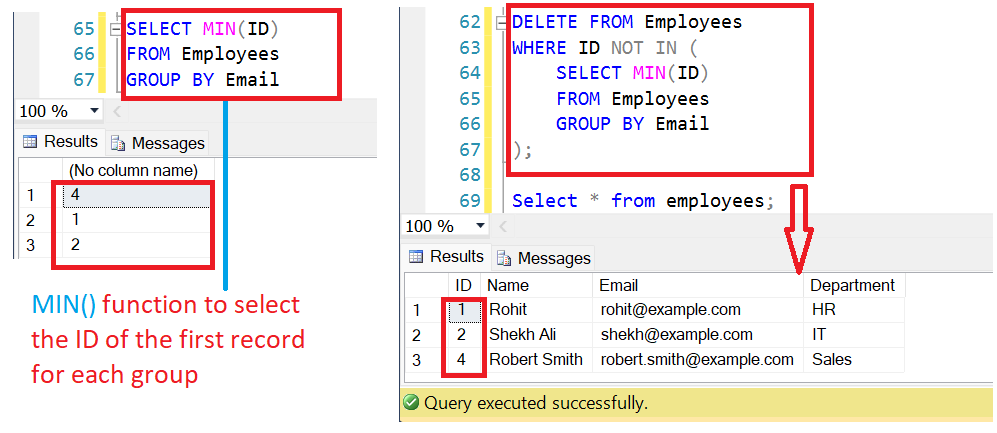
It’s important to note that in this query, the deletion of duplicates is based on the Email column and the tiebreaker is the ID column, if you want to use another column as a tiebreaker you can change the MIN(ID) function to MIN(other_column) and the GROUP BY clause to the column you want to use as a tiebreaker.
We can also verify the result by running the SELECT statement to check that only the unique records are left in the table.
SELECT * FROM Employees;
| Id | Name | Department | |
|---|---|---|---|
| 1 | Rohit | rohit@example.com | HR |
| 2 | Shekh Ali | shekh@example.com | IT |
| 4 | Robert Smith | robert.smith@example.com | Sales |
Method 3: Using the CTE and ROW_NUMBER() Function
The third way to delete duplicate rows is by using the ROW_NUMBER() function. This function assigns a unique number to each row within a result set, making it easy to identify and delete duplicate rows.
Syntax:
WITH CTE AS
(SELECT Column_Name, ROW_NUMBER() OVER(PARTITION BY Column_Name ORDER BY Column_Name) AS RN
FROM Table_Name)
DELETE FROM CTE
WHERE RN > 1
Example:
WITH CTE AS
(
SELECT *, ROW_NUMBER() OVER (PARTITION BY Email ORDER BY ID) AS RN
FROM Employees
)
DELETE FROM CTE
WHERE RN > 1;
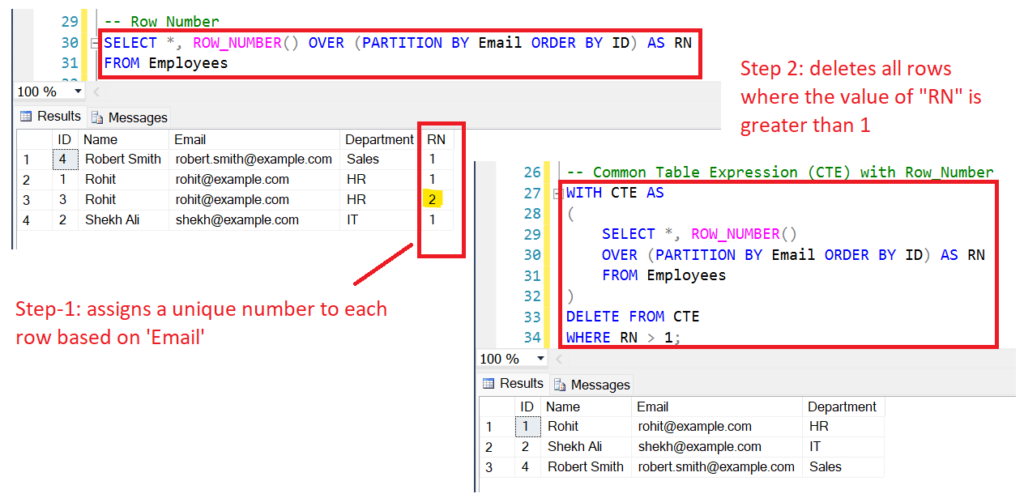
In this query, we are using a Common Table Expression (CTE) to assign a unique number to each row based on the value of the “Email” column using the ROW_NUMBER() function.
The query then deletes all the rows where the value of “RN” is greater than 1 and effectively keeping one of the duplicate records and deleting the rest.
Let’s run the SELECT statement to check the unique records in the table.
SELECT * FROM Employees;
| Id | Name | Department | |
|---|---|---|---|
| 1 | Rohit | rohit@example.com | HR |
| 2 | Shekh Ali | shekh@example.com | IT |
| 4 | Robert Smith | robert.smith@example.com | Sales |
Method 4: Using RANK function to delete duplicate rows
The following is an example of how you can use the RANK() function to delete duplicate rows from a table:
Example:
WITH CTE AS
(
SELECT *, RANK() OVER (PARTITION BY Email ORDER BY ID) AS RNK
FROM Employees
)
The above query creates a Common Table Expression (CTE) that assigns a unique rank to each row based on the value of the “Email” column, using the RANK() function. The query then deletes all the rows where the value of “RNK” is greater than 1, effectively keeping one of the duplicate records and deleting the rest of the duplicate records from the table.
Conclusion
You know that the Duplicate data can be a major headache when working with SQL Server tables. However, as you have seen that there are several different ways to delete duplicate rows in SQL Server. Whether you are using the DELETE statement, the GROUP BY clause, or the ROW_NUMBER() or RANK() function, you’ll be able to quickly and easily eliminate duplicate data from your tables.
Articles you might also like:
- Delete vs Truncate vs Drop in SQL Server: What is the Difference between DELETE, TRUNCATE and DROP in SQL?
- Having VS Where Clause in SQL | Explore the main Differences between Where and Having Clause in SQL
- UNION vs UNION ALL in SQL SERVER: A Comparative Analysis of Differences and Uses
- Types of Joins in SQL Server
- Function vs Stored procedure in SQL Server
- Stored Procedure in SQL Server With Examples
- Create, Alter, and Drop Database In SQL Server
- SQL Comparison Operators (Less than, Greater than, Equal, Not Equal operators)
- Primary Key Constraint In SQL Server
- View In SQL | Types Of Views In SQL Server
- SQL Server Trigger Update, Insert, Delete Examples
- SQL pivot tables: Understanding pivot tables in SQL Server

- C# 12 New Features in 2025: What’s New with .NET 8 - April 11, 2025
- Difference Between WCF and Web API with Examples: A Comprehensive Guide - March 27, 2025
- PUT vs PATCH vs POST in REST API: Key Differences Explained With Examples - March 23, 2025